


Complete PySpark Developer Course (Spark with Python)
用数百个实际例子深入学习PySpark。做一个完整的PySpark开发者。设置一个Hadoop集群。
你会学到什么
成功的PySpark开发人员的完整课程
Hadoop单节点集群设置并与Spark 2.x和Spark 3.x集成
PySpark (Windows和Unix)安装的完整流程
详细的HDFS课程
Python速成班
Spark介绍
理解迷你会话
Spark RDD基础,运营,坚持。解决问题的实例。
Spark 集群架构-执行,纱,JVM进程,DAG调度程序,任务调度程序
Spark 共享变量
Spark SQL架构,催化剂优化器,火山迭代器模型,钨执行引擎
数据框架基础
数据框行、列和数据类型。实例。
使用数据框架的ETL(提取应用程序接口、转换应用程序接口和加载应用程序接口)。实例。
优化和管理-连接策略、驱动程序配置、执行器配置等
流派:电子学习| MP4 |视频:h264,1280×720 |音频:AAC,44.1 KHz
语言:英语+中英文字幕(云桥CG资源站 机译)|大小:7.15 GB |时长:29h 1m
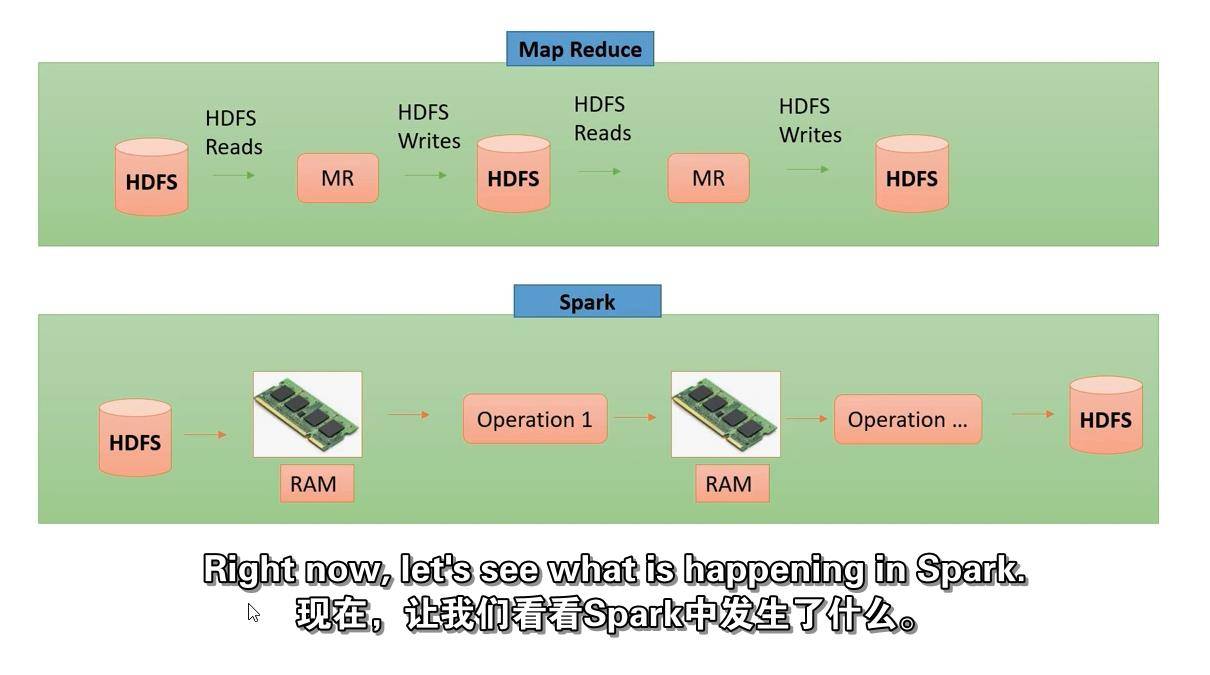

描述
这是一门完整的PySpark开发人员课程,面向数据工程师和数据科学家以及希望以有效方式处理大数据的其他人。我们将涵盖以下主题和更多内容
成功的PySpark开发人员的完整课程
设置Hadoop单节点集群,并将其与Spark 2.x和Spark 3.x集成
独立PySpark (Unix和Windows操作系统)安装的完整流程
详细的HDFS命令和建筑。
Python速成班
Spark 介绍(为什么开发Spark,Spark特性,Spark组件)
理解迷你会话
火花RDD基础
如何创建关系数据库
RDD运营(转型和行动)
Spark 集群架构-执行,纱,JVM进程,DAG调度程序,任务调度程序
RDD坚持
Spark共享变量-广播
Spark共享变量-累加器)
Spark SQL架构,催化剂优化器,火山迭代器模型,钨执行引擎,不同的基准
催化剂优化器和火山迭代器模型的区别
Spark常用函数-版本、范围、创建数据框架、sql、表、SparkContext、conf、read、udf、newSession、stop、catalog等
DataFrame内置函数-新的列函数、加密函数、字符串函数、regexp函数、日期函数、null函数、集合函数、na函数、数学和统计函数、分解函数、展平函数、格式化和json函数
什么是分区,
什么是重新分区
什么是联合
重新分区与合并
抽取- csv文件、文本文件、Parquet文件、orc文件、json文件、avro文件、hive、jdbc
数据框架基础
什么是数据框
数据帧来源
数据框特征
数据框架组织
数据框行,
数据框列
数据类型。实例。
使用数据框架执行ETL
-提取原料药
-转换应用程序接口
-加载应用程序接口
-实例。
优化和管理-连接策略、驱动程序配置、并行配置、执行器配置等
这门课是给谁的
任何愿意学习像PySpark这样的高级大数据技术的信息技术专业人员。
想学Spark的Python开发者。
数据工程师和数据科学家。


Genre: eLearning | MP4 | Video: h264, 1280×720 | Audio: AAC, 44.1 KHz
Language: English | Size: 7.15 GB | Duration: 29h 1m
Learn PySpark in depth with hundreds of Practical examples. Be a complete PySpark Developer. Set up a Hadoop Cluster.
What you’ll learn
Complete Curriculum for a successful PySpark Developer
Hadoop Single Node Cluster Set up and Integrate with Spark 2.x and Spark 3.x
Complete Flow of Installation of PySpark (Windows and Unix)
Detailed HDFS Course
Python Crash Course
Introduction to Spark
Understand SparkSession
Spark RDD Fundamentals, Operations, Persistence. Practical Examples to solve problems.
Spark Cluster Architecture – Execution, YARN, JVM Processes, DAG Scheduler, Task Scheduler
Spark Shared Variables
Spark SQL Architecture, Catalyst Optimizer, Volcano Iterator Model, Tungsten Execution Engine
DataFrame Fundamentals
DataFrame Rows, Columns and DataTypes. Practical examples.
ETL Using DataFrame (Extraction APIs, Transformation APIs, and Loading APIs). Practical Examples.
Optimization and Management – Join Strategies, Driver Conf, Executor Conf etc
Description
This is a complete PySpark Developer course for Data Engineers and Data Scientists and others who wants to process Big Data in an effective manner. We will cover below topics and more
Complete Curriculum for a successful PySpark Developer
Set up Hadoop Single Node Cluster and Integrate it with Spark 2.x and Spark 3.x
Complete Flow of Installation of Standalone PySpark (Unix and Windows Operating System)
Detailed HDFS Commands and Architecture.
Python Crash Course
Introduction to Spark (Why Spark was Developed, Spark Features, Spark Components)
Understand SparkSession
Spark RDD Fundamentals
How to Create RDDs
RDD Operations (Transformations & Actions)
Spark Cluster Architecture – Execution, YARN, JVM Processes, DAG Scheduler, Task Scheduler
RDD Persistence
Spark Shared Variables – Broadcast
Spark Shared Variables – Accumulators)
Spark SQL Architecture, Catalyst Optimizer, Volcano Iterator Model, Tungsten Execution Engine, Different Benchmarks
Difference between Catalyst Optimizer and Volcano Iterator Model
Spark Commonly Used Functions – Version, range, createDataFrame, sql, table, SparkContext, conf, read, udf, newSession, stop, catalog etc
DataFrame Built-in functions – new column functions, encryption functions, string functions, regexp functions, date functions, null functions, collection functions, na functions, math and statistics functions, explode functions, flatten functions, formatting and json functions
What is Partition,
What is Repartition
What is Coalesce
Repartition Vs Coalesce
Extraction – csv file, text file, Parquet File, orc file, json file, avro file, hive, jdbc
DataFrame Fundamentals
What is a DataFrame
DataFrame Sources
DataFrame Features
DataFrame Organization
DataFrame Rows,
DataFrame Columns
DataTypes. Practical examples.
Perform ETL Using DataFrame
— Extraction APIs
–Transformation APIs
— Loading APIs
— Practical Examples.
Optimization and Management – Join Strategies, Driver Conf, Parallelism Configurations, Executor Conf etc
Who this course is for
Any IT professional willing to learn advanced Big Data Technologies like PySpark.
Python Developers who wants to learn Spark.
Data Engineers and Data Scientists.
云桥CG资源站 为三维动画制作,游戏开发员、影视特效师等CG艺术家提供视频教程素材资源!
1、登录后,打赏30元成为VIP会员,全站资源免费获取!
2、资源默认为百度网盘链接,请用浏览器打开输入提取码不要有多余空格,如无法获取 请联系微信 yunqiaonet 补发。
3、分卷压缩包资源 需全部下载后解压第一个压缩包即可,下载过程不要强制中断 建议用winrar解压或360解压缩软件解压!
4、云桥CG资源站所发布资源仅供用户自学自用,用户需以学习为目的,按需下载,严禁批量采集搬运共享资源等行为,望知悉!!!
5、云桥CG资源站,感谢您的赞赏与支持!平台所收取打赏费用仅作为平台服务器租赁及人员维护资金 费用不为素材本身费用,望理解知悉!











